データリネージツール Stairlight でテーブルの依存関係をグラフにする
この記事は、datatech-jp Advent Calendar 2021 の6日目の記事です。
こんにちは、GMOペパボ株式会社でデータエンジニアをしています、@tosh2230 と申します。
5日目は よしむらさんのデータマネジメント成熟度アセスメント、データ利活用機運アセスメントを行った話 でした。アセスメントの実施例は貴重ですね。参考にしつつ所属企業ではどう進めていけばよいのか、自分なりに考えていこうと思いました。
はじめに
この記事では、先月に実装したデータリネージツール Stairlight を使って、データパイプラインで作成されるテーブル群(に見立てたテストデータ)の依存関係をグラフにしてみようと思います。*1
Stairlight をかいつまんで説明
Stairlight は、テーブルレベルのデータリネージを行うためのツールです。つくったばかりなので Pre-release 扱いです。
ざっくり機能を説明しますと、入力が SQL を含んだファイル群で、そのファイル内のクエリ文字列を正規表現で解析して、テーブル間の依存関係を出力します。
PyPi に パッケージ、GitHub にソースコードを公開しています。
機能の詳細については、こちらのブログ記事をご参照ください。
ライブラリとしても使えます
上記のブログ記事では、CLI のコマンドを中心に紹介しましたが、Stairlight はライブラリとしてアプリケーションに組み込むことができます。
正確には、最初からライブラリとして実装していて、公開にあたって CLI でラップした、という順序になります。 ライブラリの関数と CLI のコマンドは基本的に一緒にしています。
デモ用のアプリケーションをつくりました
見ていただいたほうが話が早いので、デモ用の Web アプリケーションを公開しました! *2
ダークモードにしたほうが見やすいかもしれません。
ここからは、このアプリケーションでやっていることを紹介していきます。
初期表示
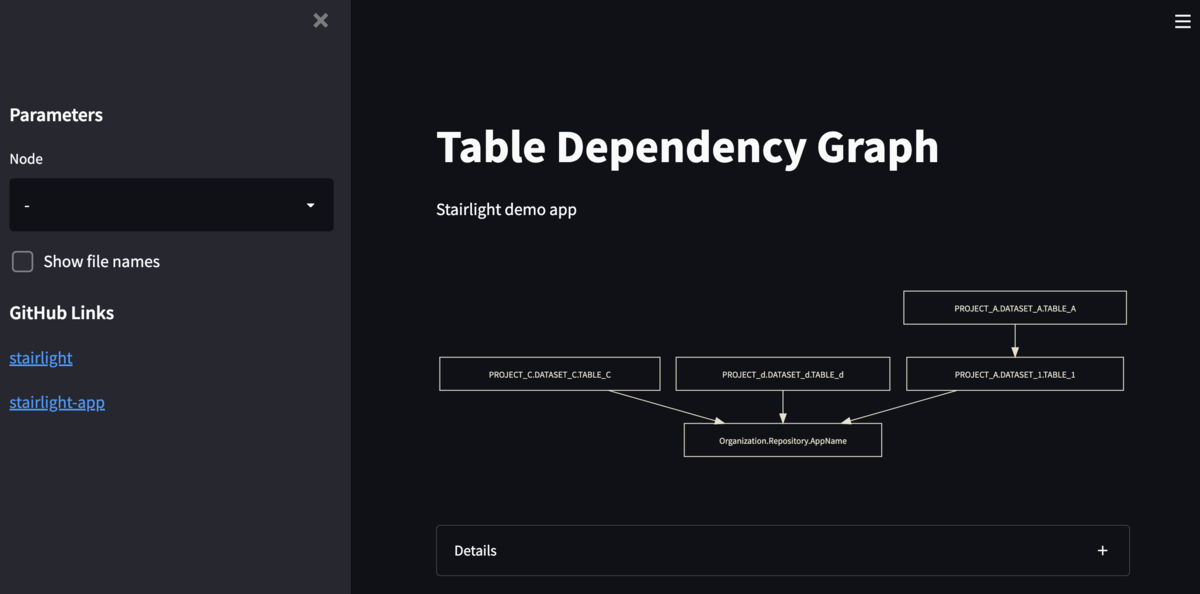
初期画面では、入力ファイルすべてを読み取ったグラフが表示されています。上から下がデータが流れる方向です。
グラフの中にあるノード(グラフ中の四角) が、テーブルやアプリケーションを指します。*3 その間のエッジ(矢印) が、ノード間の依存関係を表しています。
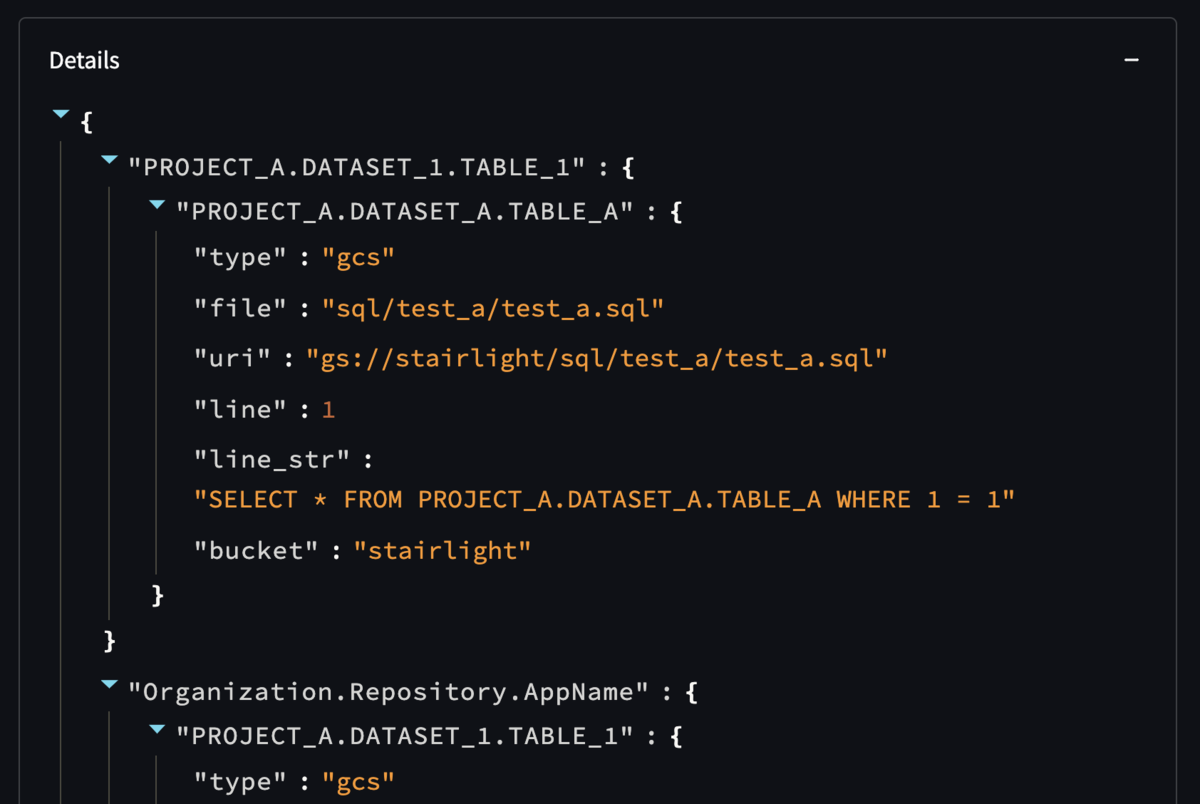
グラフ下の Details を展開すると、グラフのデータソースである JSON 文字列が表示されます。
これは、CLI のコマンド stairlight を実行した結果と同じ内容で、ライブラリにおける StairLight クラスの mapped プロパティの値を出力しています。
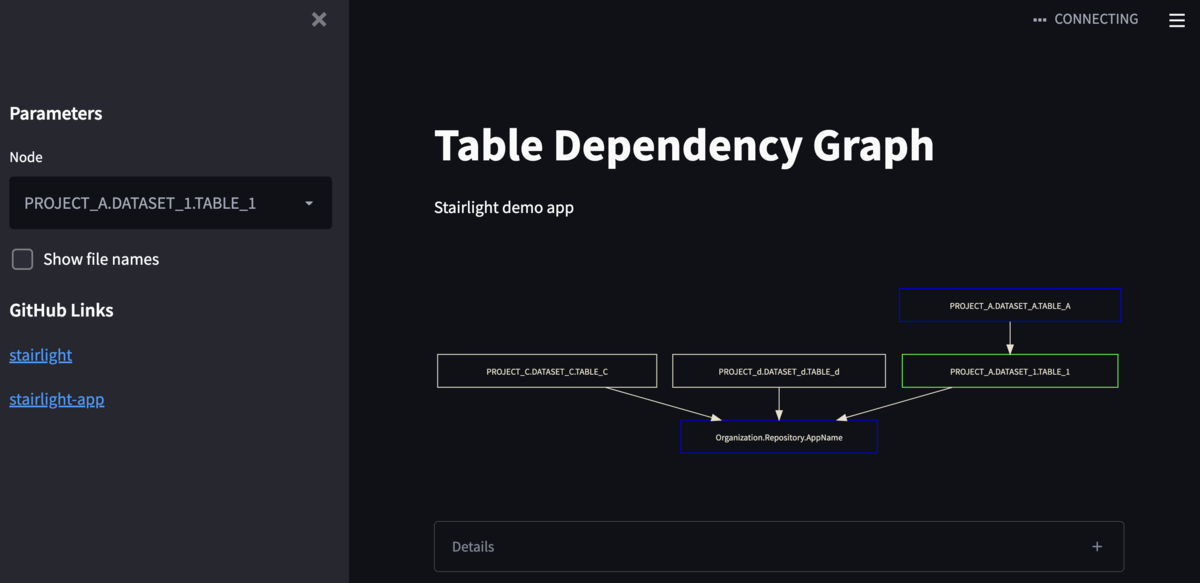
ノードを選んでみる
サイドバーにドロップダウンリストを設置しており、これを使って特定のノードを選ぶことができます。
ドロップダウンリストを操作すると、選択したノードと、その上流・下流に位置するノードの色が変化します。これによって、選択したノードのデータがどの経路で作成され、そしてどのデータに影響するのかを視覚的に把握することができます。
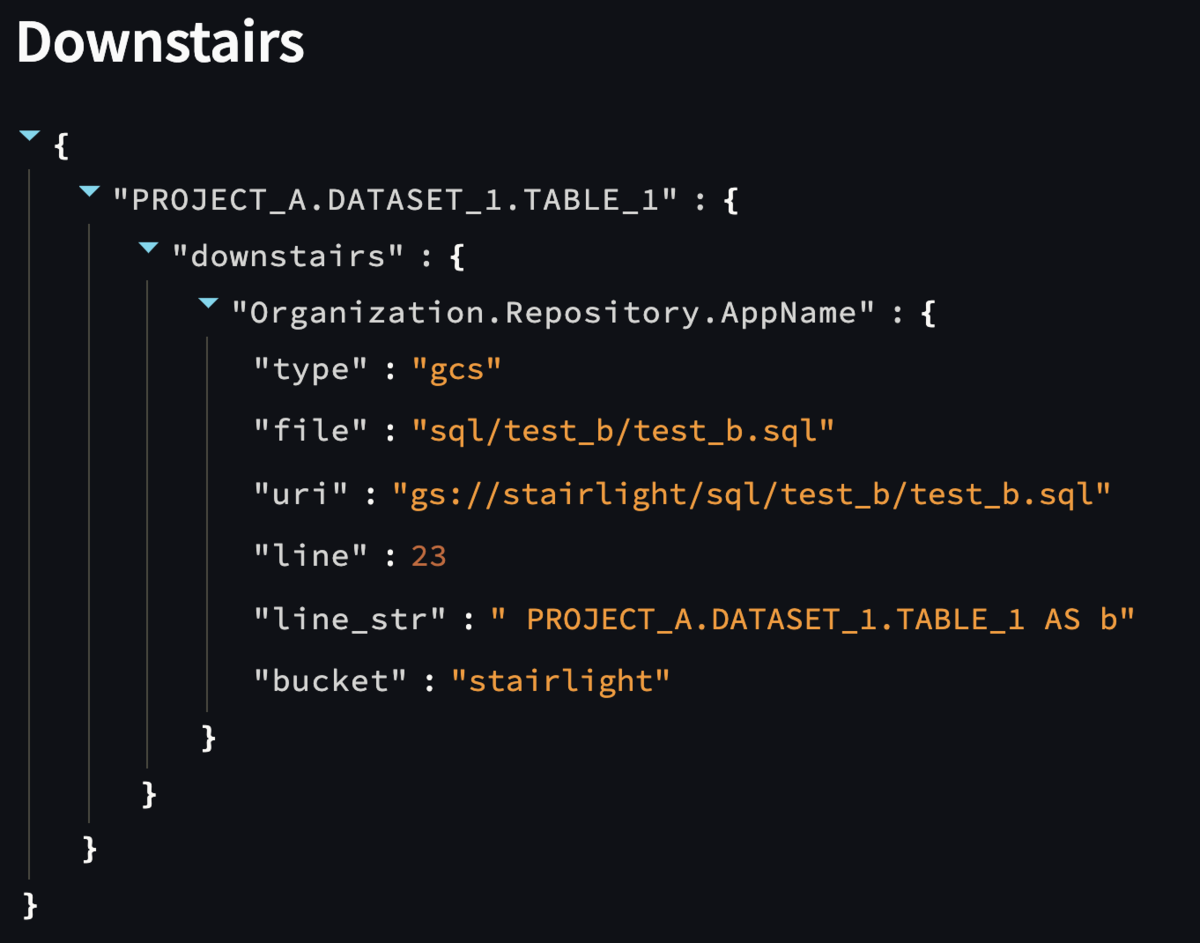
また、グラフ下の Details の内容も変化しています。選択したノードから見て、上流 (Upstairs) と 下流 (Downstairs) の属性情報がそれぞれ表示されます。ライブラリの実装でいえば、前者が StairLight.up()、後者が StairLight.down() の結果を出力しています。

ファイル名を表示
また、Show file names チェックボックスをオンにすると、エッジの横に ファイル名のラベルが表示されます。これにより、どのファイルによって依存関係が生じているのかを確認できます。
デモアプリケーションの構成
このアプリケーションでは、主に下記のライブラリ・サービスを使用しています。
- Google Cloud Run: アプリケーション実行環境
- Google Cloud Storage: 入力ファイルの保存ストレージ
- 入力ファイルはこちらと同じです。
- Streamlit: Web フロントエンドフレームワーク
- Graphviz: グラフ描画ライブラリ
- Stairlight
なお、今回の Cloud Run & Streamlit アプリケーションは認証なしで公開していますが、前段に Cloud Load Balancing を設置すると Identity-Aware Proxy(IAP) による認証機能を追加できます。
おわりに
今回のお見せしたアプリでは Stairlight の出力結果のみでグラフを描画してみましたが、Stairlight の出力結果は単独で使うよりも、その他のデータと組み合わせることで便利になるのではと考えています。個人的には、マスタデータという位置付けかなと思います。
例えば、データウェアハウスの監査ログやジョブ実行ログと結合すれば、テーブル単位でのデータ生成時刻と流量、流入経路を把握できますので、いわゆるデータの鮮度を捕捉できるようになります。
または、センシティブなデータの有無をグラフで色付けしておくと、データセキュリティを意識した設計・運用・コミュニケーションに役立つかもしれません。
別の切り口では、--save オプションで Stairlight の出力結果を時系列で保存しておけば、データパイプラインの変遷を記録に残すことができます。問題発生時には、その変更タイミングを手がかりにソースコードを調査する、といった使い方もできそうです。
...などなど活用するアイデアはいくつかあるのですが、ツールの精度が高いことが大前提となりますので、今後も継続的な改善を続けていきたいと思います。
datatech-jp Advent Calendar 2021、7日目は @nii_yan さんです!