AWS Database Migration Service による Change Data Capture: 後編
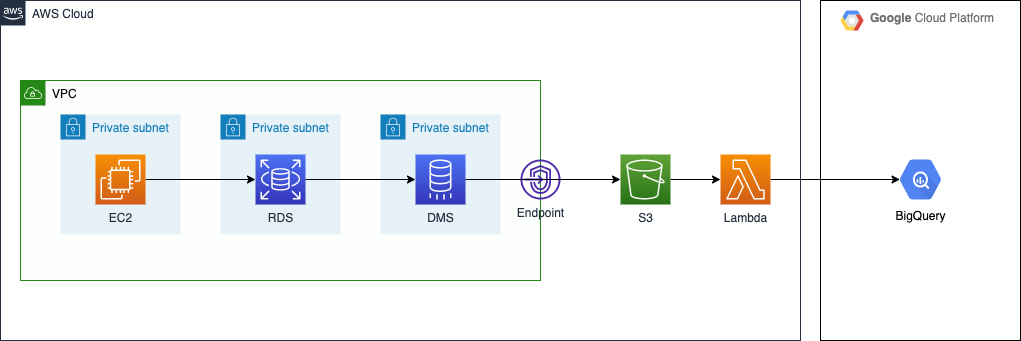
Amazon RDS から Google BigQuery への CDC 後編です。後編では、S3 に格納された Parquet ファイルのデータを BigQuery に登録する部分を扱います。
前編はこちらをご覧ください。
ソースコードは、前回同様にこちらで公開しています。
同期方法
今回は、簡易的な方法として AWS Lambda を使用しました。*1
S3 でのオブジェクト生成をトリガーに、Lambda Function が発火するようにしています。ちょうど良い機会でしたので、AWS re:Invent 2021 で発表された Amazon EventBridge による S3 イベント通知 を使ってみました。S3 バケットと Lambda Function が密結合にならず、とても嬉しいアップデートだなと実感しました。
Lambda Function
Lambda Function では Parquet ファイルの読み込みと BigQuery へのロードを行っています。 ライブラリとして google-cloud-bigquery を使用していますが、そのサイズは ZIP archive や Lambda Layer の上限を超えていますので、コンテナイメージ方式でデプロイしています。
FunctionLoadParquetToBigQuery: Type: AWS::Serverless::Function Properties: FunctionName: load_parquet_to_bigquery PackageType: Image MemorySize: 256 Timeout: 60 Role: !GetAtt RoleFunctionLoadParquetToBigQuery.Arn Environment: Variables: GCP_SA_SECRET_NAME: cdc-rds-bq-lambda Events: EventBridge: Type: EventBridgeRule Properties: Pattern: source: - aws.s3 detail-type: - Object Created detail: bucket: name: - Fn::ImportValue: !Sub ${S3Stack}-S3BucketName object: key: - prefix: mysqlslap/ DeadLetterQueue: TargetArn: !GetAtt DeadLetterQueue.Arn Type: SQS Metadata: Dockerfile: Dockerfile DockerContext: ./load_parquet_to_bigquery DockerTag: latest
アプリケーションコード
EventBridge 経由で送信されたイベント情報をもとに、S3 にある Parquet ファイルを取得しており、Bytes オブジェクトとしてメモリに直接読み出しています。*2
def get_s3_object_body(self, bucket_name: str, key: str) -> io.BytesIO: client = boto3.resource('s3') buffer = io.BytesIO() object = client.Object(bucket_name, key) object.download_fileobj(buffer) buffer.seek(0) return buffer
DMS では S3 への出力ファイルサイズの上限を設定できますので、そのサイズに合わせて Lambda Function のメモリサイズを決めるのがよいかなと思います。
BigQuery へのロードは、(前編ではストリーミングインサートという話をしていましたが...) load_table_from_file 関数に Bytes オブジェクトを渡しています。レコードの変更履歴はすべて保持していくものですので、追記形式で書き込みを行っています。
credentials = service_account.Credentials.from_service_account_info(info=service_account_info) bq_client = bigquery.Client(credentials=credentials) destination = f"{dataset_id}.{table_id}" job_config = bigquery.LoadJobConfig( source_format=bigquery.SourceFormat.PARQUET, write_disposition=bigquery.WriteDisposition.WRITE_APPEND, autodetect=True, ) job = bq_client.load_table_from_file( file_obj=file_obj, destination=destination, job_config=job_config, ) job.result()
同期結果
このように、BigQuery にテーブルが作成されるのを確認できました。

検証の都合で同一のレコードが複数入っていますが、もとのテーブル設計がきちんとしていれば、Primary Key をもとにレコードを抽出できそうです。このテーブルは履歴情報のようなものですので、実務上はこのテーブルをベースにして最新の状態を表現するビューを作成することになると思います。
まとめ
AWS DMS を使ってキャプチャした RDS の変更を、BigQuery に同期してみました。DMS は設定項目が多いので最初はうっ、となりますが、慣れてくると細かく設定できるし便利だという見え方に変わりました。今回使用した MySQL や S3 のほかにも DMS Endpoint は複数用意されているので、AWS でのデータ移行では有力な選択肢になりそうです。